arXiv:2403.04017v1 Announce Type: new
Abstract: Automated theorem provers and formal proof assistants are general reasoning systems that are in theory capable of proving arbitrarily hard theorems, thus solving arbitrary problems reducible to mathematics and logical reasoning. In practice, such systems however face large combinatorial explosion, and therefore include many heuristics and choice points that considerably influence their performance. This is an opportunity for trained machine learning predictors, which can guide the work of such reasoning systems. Conversely, deductive search supported by the notion of logically valid proof allows one to train machine learning systems on large reasoning corpora. Such bodies of proof are usually correct by construction and when combined with more and more precise trained guidance they can be boostrapped into very large corpora, with increasingly long reasoning chains and possibly novel proof ideas. In this paper we provide an overview of several automated reasoning and theorem proving domains and the learning and AI methods that have been so far developed for them. These include premise selection, proof guidance in several settings, AI systems and feedback loops iterating between reasoning and learning, and symbolic classification problems.
(I write a monthly opinion piece for Barron’s. This one was published there in September. My previous pieces are here.)
You wouldn’t necessarily guess it from the headlines, but we may soon be talking about inflation in the past tense. After peaking at close to 10% in the summer of 2022, inflation has fallen even faster than it rose. Over the past three months inflation, as measured by the CPI, has been slightly below the Federal Reserve’s 2% target. Nearly every other measure tells a similar story.

Predicting the future is always risky. But right now, it seems like the conversation about how to fix the inflation problem is nearing its end. Soon, we’ll be having a new debate: Who, or what, should get credit for solving it?
The Fed is the most obvious candidate. Plenty of commentators are already giving it at least tentative credit for delivering that elusive soft landing. And why not? Inflation goes up. The central bank raises interest rates. Inflation goes back down. Isn’t that how it’s supposed to work?
The problem is, monetary policy does not work through magic. The Fed doesn’t simply tell private businesses how much to charge. Higher interest rates lead to lower prices only by reducing demand. And so far, that doesn’t seem to have happened – certainly not on a scale that could explain how much inflation has come down.
In the textbook story, interest rates affect prices via labor costs. The idea is that businesses normally set prices as a markup over production costs, which consist primarily of wages. When the Fed raises rates, it discourages investment spending — home construction and business spending on plant and equipment — which is normally financed with credit. Less investment means less demand for labor, which means higher unemployment and more labor market slack generally. As unemployment rises, workers, with less bargaining power vis-a-vis employers, must accept lower wages. And those lower wages get passed on to prices.
Of course this is not the only possible story. Another point of view is that tighter credit affects prices through the demand side. In this story, rather than businesses producing as much as they can sell at given costs, there is a maximum amount they can produce, often described as potential output. When demand rises above this ceiling, that’s when prices rise.
Either way, the key point — which should be obvious, but somehow gets lost in macro debates — is that prices are determined by real conditions in individual markets. The only way for higher rates to slow down rising prices, is if they curtail someone’s spending, and thereby production and employment. No business — whether it’s selling semiconductors or hamburgers — says “interest rates are going up, so I guess I’ll charge less.” If interest rates change their pricing decisions, it has to be through some combination of fall in demand for their product, or in the wages they pay.
Over the past 18 months, the Fed has overseen one of the fast increases in short-term interest rates on record. We might expect that to lead to much weaker demand and labor markets, which would explain the fall in inflation. But has it?
The Fed’s rate increases have likely had some effect. In a world where the Federal Funds rate was still at zero, employment and output might well be somewhat higher than they are in reality. Believers in monetary-policy orthodoxy can certainly find signs of a gently slowing economy to credit the Fed with. The moderately weaker employment and wage growth of recent months is, from this point of view, evidence that the Fed is succeeding.
One problem with pointing to weaker labor markets as a success story, is that workers’ bargaining power matters for more than wages and prices. As I’ve noted before, when workers have relatively more freedom to pick and choose between jobs, that affects everything from employment discrimination to productivity growth. The same tight labor markets that have delivered rapid wage growth, have also, for example, encouraged employers to offer flexible hours and other accommodations to working parents — which has in turn contributed to women’s rapid post-pandemic return to the workplace.
A more basic problem is that, whether or not you think a weaker labor market would be a good thing on balance, the labor market has not, in fact, gotten much weaker.
At 3.8%, the unemployment rate is essentially unchanged from where it was when at the peak of the inflation in June 2022. It’s well below where it was when inflation started to rise in late 2020. It’s true that quits and job vacancy rates, which many people look to as alternative measures of labor-market conditions, have come down a bit over the past year. But they still are extremely high by historical standards. The prime-age employment-population ratio, another popular measure of labor-market conditions, has continued to rise over the past year, and is now at its highest level in more than 20 years.
Overall, if the labor market looks a bit softer compared with a year ago, it remains extremely tight by any other comparison. Certainly there is nothing in these indicators to explain why prices were rising at an annual rate of over 10% in mid-2022, compared with just 2% today.
On the demand side, the case is, if anything, even weaker. As Employ America notes in its excellent overview, real gross domestic product growth has accelerated during the same period that inflation has come down. The Bureau of Economic Analysis’s measure of the output gap similarly shows that spending has risen relative to potential output over the past year. For the demand story to work, it should have fallen. It’s hard to see how rate hikes could be responsible for lower inflation during a period in which people’s spending has actually picked up.
It is true that higher rates do seem to have discouraged new housing construction. But even here, the pace of new housing starts today remains higher than at any time between 2007 and the pandemic.
Business investment, meanwhile, is surging. Growth in nonresidential investment has accelerated steadily over the past year and a half, even as inflation has fallen. The U.S. is currently seeing a historic factory boom — spending on new manufacturing construction has nearly doubled over the past year, with electric vehicles, solar panels and semiconductors leading the way. That this is happening while interest rates are rising sharply should raise doubts, again, about how important rates really are for business investment. In any case, no story about interest rates that depends on their effects on investment spending can explain the recent fall in inflation.
A more disaggregated look at inflation confirms this impression. If we look at price increases over the past three months compared with the period of high inflation in 2021-2022, we see that inflation has slowed across most of the economy, but much more so in some areas than others.

Of the seven-point fall in inflation, nearly half is accounted for by energy, which makes up less than a tenth of the consumption basket. Most of the rest of the fall is from manufactured goods. Non-energy services, meanwhile, saw only a very modest slowing of prices; while they account for about 60% of the consumption basket, they contributed only about a tenth of the fall in inflation. Housing costs are notoriously tricky; but as measured by the shelter component of the Bureau of Labor Statistics, they are rising as fast now as when inflation was at its peak.
Most services are not traded, and are relatively labor-intensive; those should be the prices most sensitive to conditions in U.S. product and labor markets. Manufactured goods and especially energy, on the other hand, trade in very internationalized markets and have been subject to well-publicized supply disruptions. These are exactly the prices we might expect to fall for reasons having nothing to do with the Fed. The distribution of price changes, in other words, suggests that slowing inflation has little to do with macroeconomic conditions within the US, whether due to Fed action or otherwise.
If the Fed didn’t bring down inflation, what did? The biggest factor may be the fall in energy prices. It’s presumably not a coincidence that global oil prices peaked simultaneously with U.S. inflation. Durable-goods prices have also fallen, probably reflecting the gradual healing of pandemic-disrupted supply chains. A harder question is whether the supply-side measures of the past few years played a role. The IRA and CHIPS Act have certainly contributed to the boom in manufacturing investment, which will raise productive capacity in the future. It’s less clear, at least to me, how much policy contributed to the recovery in supply that has brought inflation down.
But that’s a topic for another time. For now it’s enough to say: Don’t thank the Fed.
(Note: Barron’s, like most publications I’ve worked with, prefers to use graphics produced by their own team. For this post, I’ve swapped out theirs for my original versions.)




Hello! Recently I’ve been thinking about why I explain things the way I do. The usual way I write is:
- Try to learn a topic
- Read a bunch of explanations that I find confusing
- Eventually understand the topic
- Write an explanation that makes sense to me, to help others
So why do I find all these explanations so confusing? I decided to try and find out! I came up with a list of 13 patterns that make explanations hard for me to understand. For each pattern I’ll also explain what I like to do instead to avoid the issue.
these patterns are very normal
This list isn’t meant to make you feel bad about your writing. I’ve probably done all of these things! I’m certainly going to do them again! I even did at least one of them while writing this post!
But knowing that I’m likely to accidentally do these things makes it easier for me to avoid them, and it makes me more receptive to critique when people point out issues with my writing (“Julia, this is assuming a lot of knowledge that I don’t have!“).
Being aware of these patterns also helps me when reading a confusing explanation: “oh, I’m not confused by this explanation because I’m stupid, I’m confused because it’s introduced 6 new-to-me concepts and it hasn’t explained what any of them is yet!“.
why this post is framed in a negative way
I practically always write in a positive way (“X is a good practice!”) instead of in a negative way (“Y is a bad practice!”). So why am I writing about confusing patterns instead of writing about positive patterns?
Writing clearly is a LOT of work. A big part of what motivates me to put in the work to write clearly is my frustration with confusing technical explanations (“ugh, everything I read about Linux containers was SO confusing, I wish someone had just told me X Y Z…“).
But, if I’m not careful, it’s easy to reproduce the exact same confusing patterns in my own writing! And the problem with positive patterns (like “avoid introducing unnecessary jargon”) is that they seem so obvious that I trick myself into thinking I’m following them, even when I’m not! So I’m writing these down to try to keep myself honest and hopefully help you avoid some of these patterns as well.
now for the patterns!
Now that I’ve explained my motivation, let’s explain the patterns! Here’s a quick index of all of them. They’re not in any particular order.
- pattern 1: making outdated assumptions about the audience’s knowledge
- pattern 2: having inconsistent expectations of the reader’s knowledge
- pattern 3: strained analogies
- pattern 4: fun illustrations on dry explanations
- pattern 5: unrealistic examples
- pattern 6: jargon that doesn’t mean anything
- pattern 7: missing key information
- pattern 8: introducing too many concepts at a time
- pattern 9: starting out abstract
- pattern 10: unsupported statements
- pattern 11: no examples
- pattern 12: explaining the “wrong” way to do something without saying it’s wrong
- pattern 13: “what” without “why”
pattern 1: making outdated assumptions about the audience’s knowledge
I see a lot of writing, especially systems writing, that makes outdated assumptions about what the reader knows. For example, here’s a paragraph from this Git book comparing Git’s implementation of branching to other version control tools.
Nearly every VCS has some form of branching support. […] In many VCS tools, this is a somewhat expensive process, often requiring you to create a new copy of your source code directory, which can take a long time for large projects.
The outdated assumption here is that you (the reader) know how other version control systems implement branching, and that comparing other tools’ implementation of branching to Git’s implementation will help you understand branching.
But if you’re reading this and you’ve never used another version control system and never plan to, this explanation is useless! Who cares about how other version control systems implement branching? You just want to understand how Git works!
The reason this explanation is written this way is probably that the first edition of the book was published in 2009, and this assumption was probably true in 2009! Many people learning Git shortly after it was released were switching from Subversion or CVS or something and found comparisons like this helpful.
But in 2021 Git has been the dominant version control system for a long time, and most people learning Git for the first time won’t have any experience with version control other than Git.
I also sometimes see this “outdated assumptions about the audience’s knowledge” problem with newer writing. It generally happens when the writer learned the concept many years ago, but doesn’t have a lot of experience explaining it in the present. So they give the type of explanation that assumes that the reader knows approximately the same things they and their friends knew in 2005 and don’t realize that most people learning it today have a different set of knowledge.
instead: test your explanations!
Usually if I learned a concept a long time ago, it means that I’ve lost touch with what it’s like to learn it for the first time today. So running an explanation by a few people who don’t already know the concept helps to catch incorrect assumptions I’ve made.
(I bolded “don’t already know the concept” because it’s tempting to ask someone who already understands the concept for a review. But they might have the exact same blind spots as you!)
pattern 2: having inconsistent expectations of the reader’s knowledge
For example, a new language tutorial might explain a concept that almost all programmers would know, like how a for loop is used for iteration, while the writing that immediately follows implicitly assumes knowledge that many people don’t have, like how the stack works, how malloc works, etc. (thanks to Dan Luu for this example!)
The problem with this is that are probably zero people who understand malloc but don’t understand how a for loop works! And even though it sounds silly, it’s easy to accidentally write like this if you don’t have a clear idea of who you’re writing for.
instead: pick 1 specific person and write for them!
You can pick a friend, a coworker, or just a past version of yourself. Writing for just 1 person might feel insufficiently general (“what about all the other people??“) but writing that’s easy to understand for 1 person (other than you!) has a good chance of being easy to understand for many other people as well.
pattern 3: strained analogies
Sometimes when trying to explain a complex technical concept, an author will start with a real-world concept that the reader definitely understands and use a very involved analogy to compare them.
Here’s an example I made up:
Imagine our event system is like the Mississippi River. It travels through many different ecosystems, and some rain particles don’t make it all the way. Sometimes it flows at different speeds depending on environmental conditions. The Mississippi River ends in many different tributaries.
Many different kinds of fish live in the event system. Different fish have different destinations. Humans decide to live along the river and use it for different purposes. They construct dams to control the flow.
This example is a parody, but I always find this type of analogy confusing because I end up wasting a lot of time trying to analyze exactly how an event stream is different / the same as the Mississippi river instead of just learning technical facts about event streams:
I think authors do this because.. it’s kind of fun to write these Big Weird Analogies! Like, is there something in a stream processing system that’s like a dam? Maybe! It’s kind of fun to think about! But even though these can be fun to write, they’re not as fun to read – it’s a struggle to extract the actual technical facts you want to know.
instead: keep analogies to a single idea
Instead of using “big” analogies where I explain in depth exactly how an event processing system is like a river, I prefer to explain the analogy in one or two sentences to make a specific point and then leave the analogy behind.
Here are 2 ways to do that.
option 1: use “implicit” metaphors
For example, if we’re talking about streams, I might write:
Every event in a stream flows from a producer to a consumer.
Here I’m using the word “flow”, which is definitely a water metaphor. I think this is great – it’s an efficient way to evoke an idea of directionality and the idea that there are potentially a large number of events.
I put together a bunch more metaphors in this style in Metaphors in man pages.
option 2: use a very limited analogy
For example, here’s a nice explanation from When costs are nonlinear, keep it small by Jessica Kerr that explains batching using an analogy to doing your laundry in a batch.
We like batching. Batching is more efficient: doing ten at once is faster than doing one, one, two, one, one, etc. I don't wash my socks as soon as I take them off, because lumping them in with the next load is free.
This analogy is very clear! I think it works well because batching in laundry works for the same reasons as batching in computing – batching your laundry works because there’s a low incremental cost to adding another pair of socks to the load. And it’s only used to illustrate one idea – that batching is a good choice when there’s a low incremental cost for adding a new item.
pattern 4: fun illustrations on dry explanations
Sometimes I see authors put fun illustrations with a very dry explanation to make the explanation seem more appealing and approachable.
The goal isn’t generally to trick the reader into expecting a more friendly explanation – I think the logic is usually more like “people like fun illustrations! let’s add some!“. But no matter what the intent, the problem is that the reader can end up feeling misled.
instead: make the design reflect the style of the explanation
There are lots of great examples of illustrated explanations where the writing is in a clear and friendly style:
On the other hand, dry explanations are useful too! Nobody expects the Intel instruction-set reference to be light reading! The writing is dry and technical, and the design is very utilitarian, which matches the style of the writing.
pattern 5: unrealistic examples
Here’s an unrealistic example of how to use lambda in Python:
numbers = [1, 2, 3, 4] squares = map(lambda x: x * x, numbers)
This example is unrealistic because most people don’t use map in Python – you’d use list comprehensions to do this instead.
Here’s another unrealistic example: an interface example from the Oracle docs on interfaces.
interface Bicycle {
// wheel revolutions per minute
void changeCadence(int newValue);
void changeGear(int newValue);
void speedUp(int increment);
void applyBrakes(int decrement);
}
This kind of “real world example” is super common in object oriented programming explanations but I find it quite confusing – I’ve never implemented a bicycle or car in my code! It doesn’t tell me anything about what interfaces are useful for!
instead: write realistic examples!
Here’s a more realistic example of Python lambdas, which sorts a list of children by their age. (from my post Write good examples by starting with real code) This is how I use Python lambdas the most in practice.
children = [
{"name": "ashwin", "age": 12},
{"name": "radhika", "age": 3},
]
sorted_children = sorted(children, key=lambda x: x['age'])
Here’s a more realistic example of Java interfaces.
The
Comparableinterface (from the JDK source) just has one method -- here's its full implementation.public interface Comparable<T> { int compareTo(T o); }To implement this interface, you just need to implement the
compareTomethod. And if you write a class that implements this interface (like aMoneyclass for example), then you get all sorts of useful things for free! You can sort an array ofMoneyobjects withArrays.sort! You can put them in aSortedSet!
In this Java example, of course it’s not enough to explain built-in Java interfaces – you also need realistic examples of how to create and use your own interfaces. But this post isn’t about Java interfaces so let’s move on.
pattern 6: jargon that doesn’t mean anything
Let’s talk about this sentence from this chapter on commit signing:
Git is cryptographically secure, but it’s not foolproof.
“Cryptographically secure” is unclear here because it sounds like it should have a specific technical meaning, but it’s not explained anywhere what’s actualy meant. Is it saying that Git uses SHA-1 to hash commits and it’s difficult to generate SHA-1 hash collisions? I don’t know!
Using jargon in a meaningless way like this is confusing because it can trick the reader into thinking something specific is being said, when the information they need is not actually there. (the chapter doesn’t explain anywhere what’s meant by “cryptographically secure” in this context)
instead: Avoid jargon where it’s not needed
A lot of the time I find I can communicate what I need to without using any jargon at all! For example, I’d explain why commit signing is important like this:
When making a Git commit, you can set any name and email you want! For example, I can make a commit right now saying I'm Linus Torvalds like this:git commit -m"Very Serious Kernel Update" \ --author='Linus Torvalds <torvalds@linux-foundation.org>'
pattern 7: missing key information
Sometimes explanations of a concept are missing the most important idea to understand the concept. For example, take this explanation from this chapter on the Git object model (which by the way has a nice concrete example of how to explore Git’s object model):
Git is a content-addressable filesystem. Great. What does that mean? It means that at the core of Git is a simple key-value data store. What this means is that you can insert any kind of content into a Git repository, for which Git will hand you back a unique key you can use later to retrieve that content.
This paragraph is missing what to me is the main idea of content-addressable storage – that the key for a piece of content is a deterministic function of the content, usually a hash (though the page does later say that Git uses a SHA-1 hash). It’s important that the key is a function of the content and not just any random unique key because the idea is that the content is addressed by itself – if the content changes, then its key also has to change.
This pattern is hard to recognize as a reader because – how are you supposed to recognize that there’s a key idea missing when you don’t know what the key ideas are? So this is a case where a reviewer who understands the subject well can be really helpful.
pattern 8: introducing too many concepts at a time
Here’s an explanation of linkers from this page that I find confusing:
During the link process, the linker will pick up all the object modules specified on the command line, add some system-specific startup code in front and try to resolve all external references in the object module with external definitions in other object files (object files can be specified directly on the command line or may implicitly be added through libraries). It will then assign load addresses for the object files, that is, it specifies where the code and data will end up in the address space of the finished program. Once it’s got the load addresses, it can replace all the symbolic addresses in the object code with “real”, numerical addresses in the target’s address space. The program is ready to be executed now.
Here are the concepts in this paragraph:
- object modules (
.ofiles) - external references
- symbolic addresses
- load addresses
- system-specific startup code
It’s too much!
instead: give each concept some space to breathe
For example, I might explain “external references” like this:
if you run
objdump -d myfile.oon an object file you can see that thecallfunction calls are missing a target address, so that's why the linker needs to fill that in.33: e8 00 00 00 00 call 38 ^^^^^^^^^^^ this address is all 0s -- it needs to be filled in by the linker! with the actual function that's going to be called! 38: 84 c0 test %al,%al 3a: 74 3b je 77 3c: 48 83 7d f8 00 cmpq $0x0,-0x8(%rbp)
There’s still a lot of missing information here (how does the linker know what address to fill in?), but it’s a clear starting point and gives you questions to ask.
pattern 9: starting out abstract
Imagine I try to explain to you what a Unix signal using the definition from Wikipedia.
Signals are a limited form of inter-process communication (IPC), typically used in Unix, Unix-like, and other POSIX-compliant operating systems. A signal is an asynchronous notification sent to a process or to a specific thread within the same process to notify it of an event. Signals originated in 1970s Bell Labs Unix and were later specified in the POSIX standard.
By itself, this probably isn’t going to help you understand signals if you’ve never heard of them before! It’s very abstract and jargon-heavy (“asynchonous notification”, “inter-process communication”) and doesn’t have any information about what Unix signals are used for in practice.
Of course, the Wikipedia explanation isn’t “bad” exactly – it’s probably written like that because teaching people about signals for the first time isn’t really the goal of the Wikipedia article on signals.
instead: start out concrete
For example, I wrote this page explaining signals a few years ago.
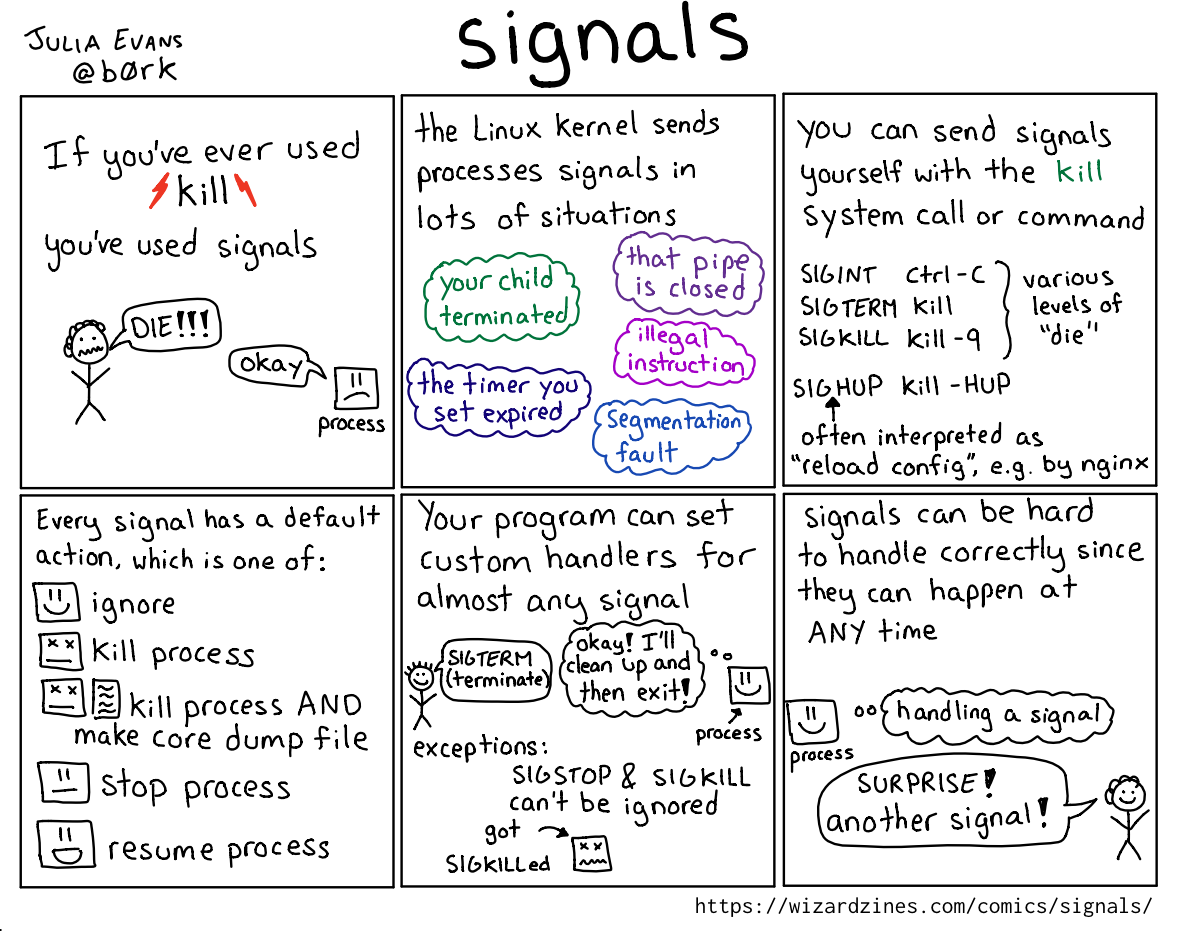
I start out by relating signals to the reader’s experience (“have you used
kill? you’ve used signals!“) before explaining how they work.
pattern 10: unsupported statements
Here’s an explanation of C header files, from this page.
In modern C, header files are crucial tools that must be designed and used correctly. They allow the compiler to cross-check independently compiled parts of a program.
Headers declare types, functions, macros etc that are needed by the consumers of a set of facilities. All the code that uses any of those facilities includes the header. All the code that defines those facilities includes the header. This allows the compiler to check that the uses and definitions match.
This says “In modern C, header files are crucial tools…” (which is true), but it doesn’t explain why header files are crucial. This of course wouldn’t be a problem if the audience already understood why header files in C are important (it’s a very fundamental concept!). But the whole point here is to explain header files, so it needs to be explained.
instead: Prove that your statements are true!
For example, I might write:
Almost every C program includes header files. For example, if you've ever written
#include <stdio.h>at the beginning of a C program,stdio.his a header file.#includebasically tells the C preprocessor to paste the contents ofstdio.hat the beginning of the program.One reason header files are important is that they define types and constants you need in your programs. For example, this code by itself will fail to compile with the error
error: unknown type name 'FILE', because theFILEtype is undefined.int main() { FILE *fp; fp = fopen("data.txt", "w"); }
FILEis defined instdio.hand if you add a#include <stdio.h>, at the top, then the program will compile.
This example program lets the reader actually run that program themselves and verify that it doesn’t compile if they want – they don’t have to take my word for it!
pattern 11: no examples
Another problem with the previous explanation of header files is – there aren’t any examples! Leaving out examples makes it harder for the reader to relate the new terminology to their own experiences.
Almost anyone who’s ever written a C program has definitely used header files,
so a simple example (like mentioning stdio.h) can really help.
In that header files example, I replaced
In modern C, header files are crucial tools…
with an explanation that includes a simple example:
Almost every C program includes header files -- if you've ever seen something like#includeat the beginning of a C program,stdio.his a header file.
pattern 12: explaining the “wrong” way to do something without saying it’s wrong
Here’s a pattern I see sometimes in tutorials (though unfortunately I don’t have an example):
- Explain the “wrong” way of doing something without saying up front that it’s wrong
- Later on, show the consequences of doing the “wrong” thing
- Explain the “right” way
I think the intention of this is to imitate the real-life experience of making mistakes. Usually when you make a mistake, you don’t know that it’s wrong at the time!
But often the reader will end up feeling misled or confused about which way is actually “correct”. And it’s possible that they would never even have made that particular mistake on their own!
instead: here are four options for presenting mistakes
Here are a few ways of accomplishing the same thing without misleading the reader:
- Frame the “wrong” thing as an experiment (“what if we try doing it X way?”)
- State an incorrect belief the reader might have: (“You might think that the command line tool would need to run as root (because it’s talking to the kernel, but…“)
- Explain a common mistake (for example “Avoid Striding and Slicing in a Single Expression” in Effective Python)
- Tell a story about a mistake you made and why it caused problems (here’s one of mine: Why Ruby’s Timeout is dangerous (and Thread.raise is terrifying))
Talking about mistakes is very important, just say up front that the thing is a mistake!
pattern 13: “what” without “why”
I very often see people introduce new technologies with a list of features instead of explaining why people choose the technology.
For example, the kubernetes homepage lists a bunch of Kubernetes’ features: automated rollouts and rollbacks, service discovery and load balancing, storage orchestration, secret and configuration management, automatic bin packing, etc. This kind of feature list is pretty common on a project homepage, but by itself it doesn’t help someone understand whether Kubernetes is right for them.
I think one reason writers leave out the “why” is that it’s hard to write a simple universal answer to “why do people use Kubernetes?”. There are a lot of reasons! And if you get the “why” wrong, it’s very noticeable and it feels embarrassing. So it feels safer to just list some features and move on.
But as a reader, I find that a weak “why” is much better than no “why”. I’d rather read “well, we use Kubernetes because it provides a decent basic deployment system and GKE means we don’t have to think about servers” than an attempt at covering every single company’s business reasons for using Kubernetes.
instead: talk about your reasons for using the technology
Of course, if you have a clear universal explanation of the problems a technology solves, that’s great. But I think a lot of the time authors (including me!!) just don’t have a great grasp of why other people are choosing a given technology. That’s okay!
If you don’t feel you can give a universal “why”, I think it’s better to just be open about that and give an example from your personal experience.
For example, I might say about Kubernetes:
The only problem I've solved with Kubernetes was: we had a distributed cron job system (Chronos) that wasn't working reliably (cron jobs would sometimes just not run), and we replaced the system with Kubernetes. Kubernetes' distributed cron was a lot more reliable.
This isn’t a good explanation of why people in general use Kubernetes! But I find reading many specific personal stories like this WAY more helpful than an attempt at cramming “here’s what’s Kubernetes is for” into a few paragraphs.
I want to be clear here that even just explaining your own personal experience isn’t that easy. Technology projects can be messy, and sometimes their goals change in the middle. I started out trying to give an example of why I’ve used Envoy and I realized I would need to think about it for several hours and have a few conversations with old coworkers to explain it coherently so I decided to use a different example.
that’s all for now!
Originally I thought it would be simple to put together these patterns (“there are so many confusing explanations!“) but it was surprisingly hard to articulate exactly what was confusing to me about each explanation in a convincing way.
It’s definitely incomplete, but I’ve already spent two weeks and 3000 words on it so I’ll stop here and I’d love to hear what I’ve missed :)
thanks to Laura, Dan, Kamal, Alyssa, Lindsey, Paul, Ivan, Edith, Hazem, Anton, and John for helping improve this post
translations
here is a translation:

Washington, DC
(I write a more-or-less monthly opinion piece for Barron’s. This is my contribution for March 2023; you can find the earlier ones here.)
When interest rates go up, businesses spend less on new buildings and equipment. Right?
That’s how it’s supposed to work, anyway. To be worth doing, after all, a project has to return more than the cost of financing it. Since capital expenditure is often funded with debt, the hurdle rate, or minimum return, for capital spending ought to go up and down with the interest rate. In textbook accounts of monetary policy, this is a critical step in turning rate increases into slower activity.
Real economies don’t always match the textbook, though. One problem: market interest rates don’t always follow the Federal Reserve. Another, perhaps even more serious problem, is that changes in interest rates may not matter much for capital spending.
A fascinating new study raises new doubts about how much of a role interest rates play in business investment.
To clarify the interest-investment link, Niels Gormsen and Kilian Huber — both professors at the University of Chicago Booth School of Business — did something unusual for economists. Instead of relying on economic theory, they listened to what businesses themselves say. Specifically, they (or their research assistants) went through the transcripts of thousands of earnings calls with analysts, and flagged any mention of the hurdle rate or required return on new capital projects.
What they found was that quoted hurdle rates were consistently quite high — typically in the 15-20% range, and often higher. They also bore no relationship to current interest rates. The federal funds rate fell from 5.25% in mid-2007 to zero by the end of 2008, and remained there through 2015. But you’d never guess it from the hurdle rates reported to analysts. Required returns on new projects were sharply elevated over 2008-2011 (while the Fed’s rate was already at zero) and remained above their mid-2000s level as late as 2015. The same lack of relationship between interest rates and investment spending is found at the level of individual firms, suggesting, in Gormsen and Huber’s words, that “fluctuations in the financial cost of capital are largely irrelevant for [business] investment.”
While this picture offers a striking rejection of the conventional view of interest rates and investment spending, it’s consistent with other research on how managers make investment decisions. These typically find that changes in the interest rate play little or no role in capital spending.
If businesses don’t look at interest rates when making investment decisions, what do they look at? The obvious answer is demand. After all, low interest rates are not much of an incentive to increase capacity if existing capacity is not being used. In practice, business investment seems to depend much more on demand growth than on the cost of capital.
(The big exception is housing. Demand matters here too, of course, but interest rates also have a clear and direct effect, both because the ultimate buyers of the house will need a mortgage, and because builders themselves are more dependent on debt financing than most businesses are. If the Fed set the total number of housing permits to be issued across the country instead of a benchmark interest rate, the effects of routine monetary policy might not look that different.)
If business investment spending is insensitive to interest rates, but does respond to demand, that has implications for more than the transmission of monetary policy. It helps explain both why growth is so steady most of the time, and why it can abruptly stall out.
As long as demand is growing, business investment spending won’t be very sensitive to interest rates or other prices. And that spending in turn sustains demand. When one business carries out a capital project, that creates demand for other businesses, encouraging them to expand as well. This creates further demand growth in turn, and more capital spending. This virtuous cycle helps explain why economic booms can continue in the face of all kinds of adverse shocks — including, sometimes, efforts by the Fed to cut them off.
On the other hand, once demand falls, investment spending will fall even more steeply. Then the virtuous cycle turns into a vicious one. It’s hard to convince businesses to resume capital spending when existing capacity is sitting idle. Each choice to hold back on investment, while individually rational, contributes to an environment where investment looks like a bad idea.
This interplay between business investment and demand was an important part of Joseph Schumpeter’s theory of business cycles. It played a critical role in John Maynard Keynes’ analysis of the Great Depression. Under the label multiplier-accelerator models, it was developed by economists in the decades after World War II. (The multiplier is the link from investment to demand, while the accelerator is the link from demand growth to investment.) These theories have since fallen out of fashion among economists. But as the Gormsen and Huber study suggests, they may fit the facts better than today’s models that give decisive importance to the interest rate controlled by the Fed.
Indeed, we may have exaggerated the role played in business cycles not just of monetary policy, but of money and finance in general. The instability that matters most may be in the real economy. The Fed worries a great deal about the danger that expectations of higher inflation may become self-confirming. But expectations about real activity can also become unanchored, with even greater consequences. Just look at the “jobless recoveries” that followed each of the three pre-pandemic recessions. Weak demand remained stubbornly locked in place, even as the Fed did everything it could to reignite growth.
In the exceptionally strong post-pandemic recovery, the Fed has so far been unable to disrupt the positive feedback between rising incomes and capital spending. Despite the rate hikes, labor markets remain tighter than any time in the past 20 years, if not the past 50. Growth in nonresidential investment remains fairly strong. Housing starts have fallen sharply since rates began rising, but construction employment has not – at least not yet. The National Federation of Independent Business’s survey of small business owners gives a sharply contradictory picture. Most of the respondents describe this as a very poor moment for expansion, yet a large proportion say that they themselves plan to expand and increase hiring. Presumably at some point this gap between what business owners are saying and what they are doing is going to close – one way or the other.
If investment responded strongly to interest rates, it might be possible for the Fed to precisely steer the economy, boosting demand a little when it’s weak, cooling it off when it gets too hot. But in a world where investment and demand respond mainly to each other, there’s less room for fine-tuning. Rather than a thermostat that can be turned up or down a degree or two, it might be closer to the truth to say that the economy has just two settings: boom and bust.
At its most recent meeting, the Fed’s forecast was for the unemployment rate to rise one point over the next year, and then stabilize. Anything is possible, of course. But in the seven decades since World War Two, there is no precedent for this. Every increase in the unemployment rate of a half a point has been followed by a substantial further rise, usually of two points or more, and a recession. (A version of this pattern is known as the Sahm rule.) Maybe we will have a soft landing this time. But it would be the first one.
(I write a monthly opinion piece for Barron’s. This is my contribution for November 2022.)
How much of our inflation problem is really a housing-cost problem?
During the first half of 2021, vehicle prices accounted for almost the whole rise in inflation. For much of this year, it was mostly energy prices.
But today, the prices of automobiles and other manufactured goods have stabilized, while energy prices are falling. It is rents that are rising rapidly. Over the past three months, housing costs accounted for a full two-thirds of the inflation in excess of the Federal Reserve’s 2% target.
Since most Americans don’t rent their homes, the main way that rents enter the inflation statistics is through owners’ equivalent rent—the government’s estimate of how much owner-occupied homes would rent for. The big cost that homeowners actually pay is debt service on their mortgage, which the Fed is currently pushing up. There is something perverse about responding to an increase in a hypothetical price of housing by making actual housing more expensive.
Still, the housing cost problem is real. Market rents are up by over 10% in the past year, according to Zillow. While homeownership rates have recovered somewhat, they are still well below where they were in the mid-2000s. And with vacancy rates for both rental and owner-occupied homes at their lowest levels in 40 years, the housing shortage is likely to get worse.
Housing is unlike most other goods in the economy because it is tied to a specific long-lived asset. The supply of haircuts or child care depends on how much of society’s resources we can devote to producing them today. The supply of housing depends on how much of it we built in the past.
This means that conventional monetary policy is ill-suited to tackle rising housing prices. Because the housing stock adjusts slowly, housing costs may rise even when there is substantial slack in the economy. And because production of housing is dependent on credit, that’s where higher interest rates have their biggest effects. Housing starts are already down 20% since the start of this year. This will have only a modest effect on current demand, but a big effect on the supply of housing in future years. Economics 101 should tell you that if efforts to reduce demand are also reducing supply, prices won’t come down much. They might even rise.
What should we be doing instead?
First, we need to address the constraints on new housing construction. In a number of metropolitan areas, home values may be double the cost of construction. When something is worth more than it costs to produce, normally we make more of it. So, if the value of a property comes mostly from the land under it, that’s a sign that construction is falling far short of demand. The problem we need to solve isn’t that people will pay so much to live in New York or Los Angeles or Boston or Boulder, Colo. It’s that it is so difficult to add housing there.
Land-use rules are set by thousands of jurisdictions. Changing them will not happen overnight. But there are steps that can be taken now. For example, the federal government could tie transportation funding to allowing higher-density development near transit.
Second, we need more public investment. Government support—whether through direct ownership or subsidies—is critical for affordable housing, which markets won’t deliver even with relaxed land-use rules. But government’s role needn’t be limited to the low-income segment. The public sector, with its long time horizons, low borrowing costs, and ability to internalize externalities, has major advantages in building and financing middle-class housing as well.
If we look around the world, it isn’t hard to find examples of governments successfully taking a central role in housing development. In Singapore, which is hardly hostile to private business, the majority of new housing is built by the public Housing Development Board. The apartment buildings built by Vienna’s government between the world wars still provide a large share of the city’s housing. Before the privatizations under Prime Minister Margaret Thatcher, some 30% of English families lived in publicly owned housing.
In the U.S., public housing has fallen out of favor. But governments at all levels continue to support the construction of affordable housing through subsidies and incentives. Some public developers, like the Housing Production Fund of Montgomery County, Md., are finding that with cheap financing and no need to deliver returns to investors, they can compete with private developers for mixed-income housing as well. The important thing is to channel new public money to development, rather than vouchers for tenants. The latter may just bid up the price of existing housing.
Third, we should revisit rent regulation. The argument against rent control is supposed to be that it discourages new construction. But empirical studies have repeatedly failed to find any such effect. This shouldn’t be surprising. The high-rent areas where controls get adopted are precisely those where new housing construction is already tightly constrained. If not much is getting built in any case, rent regulation merely prevents the owners of existing housing from claiming windfall gains from surging demand.
No, rent control won’t boost the supply of housing. But it can limit the rise in prices until new supply comes on-line. And it’s a much bettertargeted response to rising housing costs than the policy-induced recession we are currently headed for.



Make sure to read Nicholas Nethercote’s Twenty years of Valgrind to learn about the early days, Valgrind “skins”, the influence Valgrind had on raising the bar when it comes to correctness for C and C++ programs, and why a hacker on the Rust programming language still uses Valgrind.

Next Page of Stories